Introduction
Artificial intelligence agents are becoming increasingly sophisticated, but they face a fundamental challenge: large language models (LLMs) are stateless by design. Every conversation starts fresh, every context resets, and without proper memory systems, agents forget everything the moment a session ends. This limitation has sparked a growing field of research and engineering focused on agent memory—the strategies, architectures, and tools that enable AI agents to retain information, learn from past interactions, and maintain consistency across long-running tasks. An agent memory survey reveals a rapidly evolving landscape of solutions, from simple conversation history replay to advanced semantic indexing and hierarchical memory organization. Understanding these approaches is essential for anyone building or deploying AI agents in production environments.

What Is Agent Memory?
Agent memory refers to the mechanisms and systems that enable AI agents to store, retrieve, and utilize information from past interactions and learned patterns. Unlike human memory, which is biological and continuous, agent memory is engineered—it must be explicitly designed into the system architecture. At its core, agent memory solves a critical problem: LLMs process information within a fixed context window, and once that window closes, the model has no inherent way to access previous conversations or learned facts. Agent memory bridges this gap by maintaining persistent storage outside the model's context window and intelligently retrieving relevant information when needed.
The scope of agent memory extends beyond simple conversation history. Modern agent memory systems encompass multiple memory types, each serving different purposes: short-term memory for immediate context, long-term memory for persistent knowledge, episodic memory for event-based recall, and procedural memory for learned behaviors and patterns. The challenge lies in designing these systems to be efficient, accurate, and scalable—balancing the need to retain useful information against the costs of storage, retrieval latency, and token consumption.
The Core Problem: Why Agents Need Memory
The Stateless LLM Challenge
Large language models are fundamentally stateless. Each API call is independent; the model has no built-in mechanism to remember previous conversations or accumulate knowledge over time. When a user interacts with an agent across multiple sessions, the agent starts each new conversation with zero context about the user, their preferences, or their history. This creates a jarring user experience and severely limits the agent's ability to provide personalized, contextual assistance.
Consider a customer support agent handling a complex issue. Without memory, the agent might ask the customer to repeat information they've already provided in previous tickets. A coding assistant might re-explain architectural decisions that were already discussed. A research agent might re-analyze papers it has already reviewed. These inefficiencies compound in long-running tasks where consistency and continuity are critical.
Context Window Limitations
Even within a single conversation, context windows impose hard limits. Modern LLMs like Claude or GPT-4 have context windows ranging from 100K to 200K tokens, which sounds substantial but fills quickly. A typical conversation with code snippets, documents, and detailed explanations can consume thousands of tokens. Once the context window is full, older information is lost. The naive approach—storing the entire conversation history and replaying it with each request—becomes prohibitively expensive at scale.
Real-World Consequences
The absence of proper memory systems manifests in observable problems:
- Inconsistency: Agents contradict themselves or forget decisions made earlier in a task
- Repetition: Users must re-explain context or re-provide information
- Inefficiency: Agents waste tokens re-processing information they've already seen
- Poor personalization: Agents cannot adapt to individual user preferences or patterns
- Security risks: Without proper memory isolation, agents might leak information across different users or projects
Types of Agent Memory
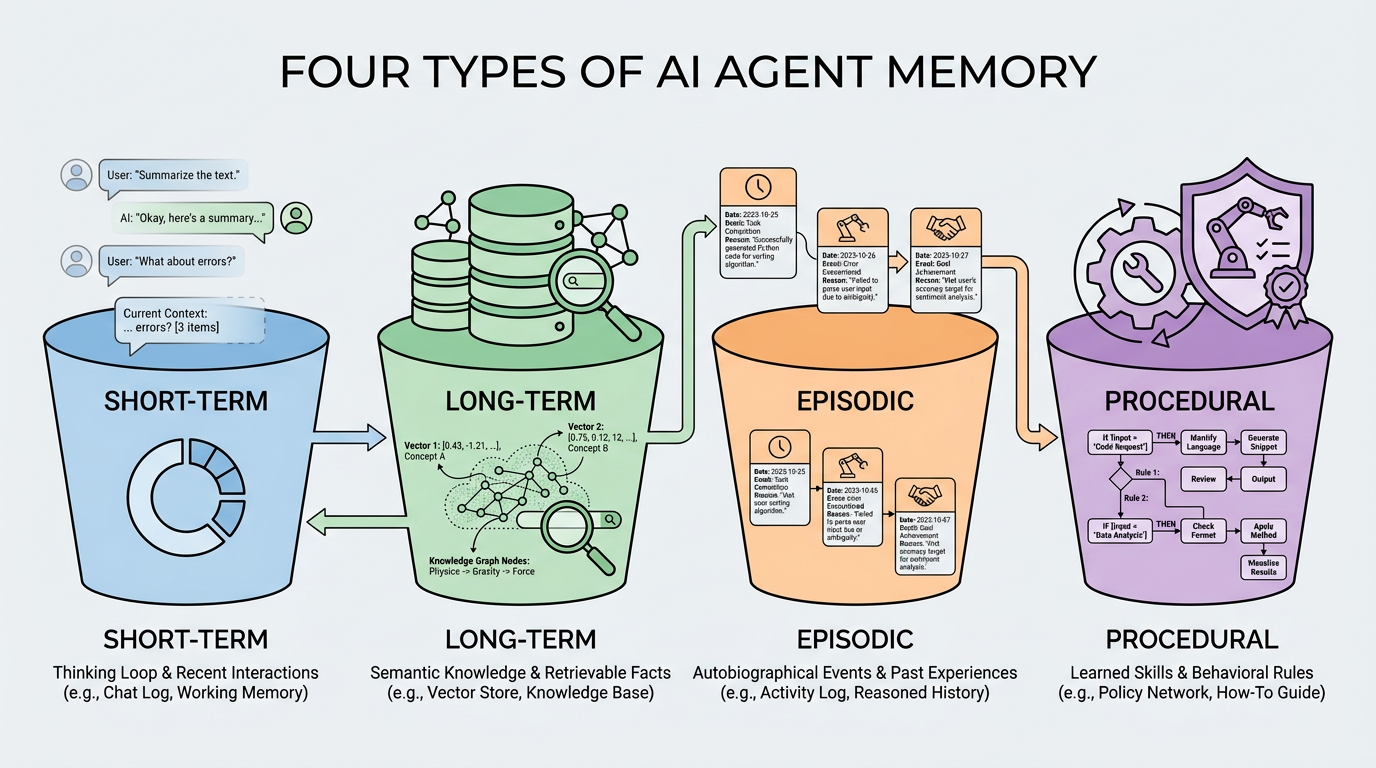
Short-Term Memory
Short-term memory captures the immediate context of an ongoing conversation. The most common implementation is a sliding window approach: the agent maintains a buffer of recent messages (typically the last 10-50 turns) and includes them in each prompt. This ensures the model has immediate context for the current task without overwhelming the context window.
Short-term memory is fast and simple but limited in scope. It cannot retain information from earlier in a long conversation or across multiple sessions. For tasks lasting hours or days, short-term memory alone is insufficient.
Long-Term Memory
Long-term memory persists beyond individual conversations and sessions. It typically uses external storage systems—databases, vector stores, or file systems—to maintain information that should be retained indefinitely. The challenge is retrieval: with potentially millions of stored facts or interactions, how does the agent efficiently find the relevant information for a given query?
Vector databases like Pinecone, Weaviate, and Milvus address this through semantic search. Information is converted into embeddings (numerical representations of meaning), and retrieval uses similarity search to find contextually relevant memories. This approach scales better than keyword search and captures semantic relationships between concepts.
Episodic Memory
Episodic memory stores specific events or interactions with rich context. Rather than storing raw conversation history, episodic memory systems extract key facts, decisions, and outcomes from interactions and store them as structured records. For example, an agent might store: "User decided to use PostgreSQL instead of MongoDB for the database (reason: better ACID guarantees for financial transactions)."
Episodic memory enables agents to recall not just what happened, but why decisions were made and what the context was. This is particularly valuable for complex projects where understanding the reasoning behind past choices is as important as the choices themselves.
Procedural Memory
Procedural memory captures learned patterns, skills, and behaviors. An agent might learn that a particular user prefers concise responses, or that a specific codebase follows a particular architectural pattern. Procedural memory is often implicit—encoded in the agent's behavior rather than explicitly stored as facts.
Some systems make procedural memory explicit by storing learned rules or patterns. For example: "When this user asks about performance optimization, prioritize database indexing strategies." This allows agents to adapt their behavior based on accumulated experience.
Memory Management Strategies
The Naive Approach: Full History Replay
The simplest strategy is to store every message in a conversation and replay the entire history with each new request. This guarantees the model has complete context but becomes expensive quickly. A conversation with 100 turns might consume 10,000+ tokens just for history, leaving little room for the actual query and response.
This approach is practical for short conversations but breaks down for long-running agents or high-volume systems where token costs become prohibitive.
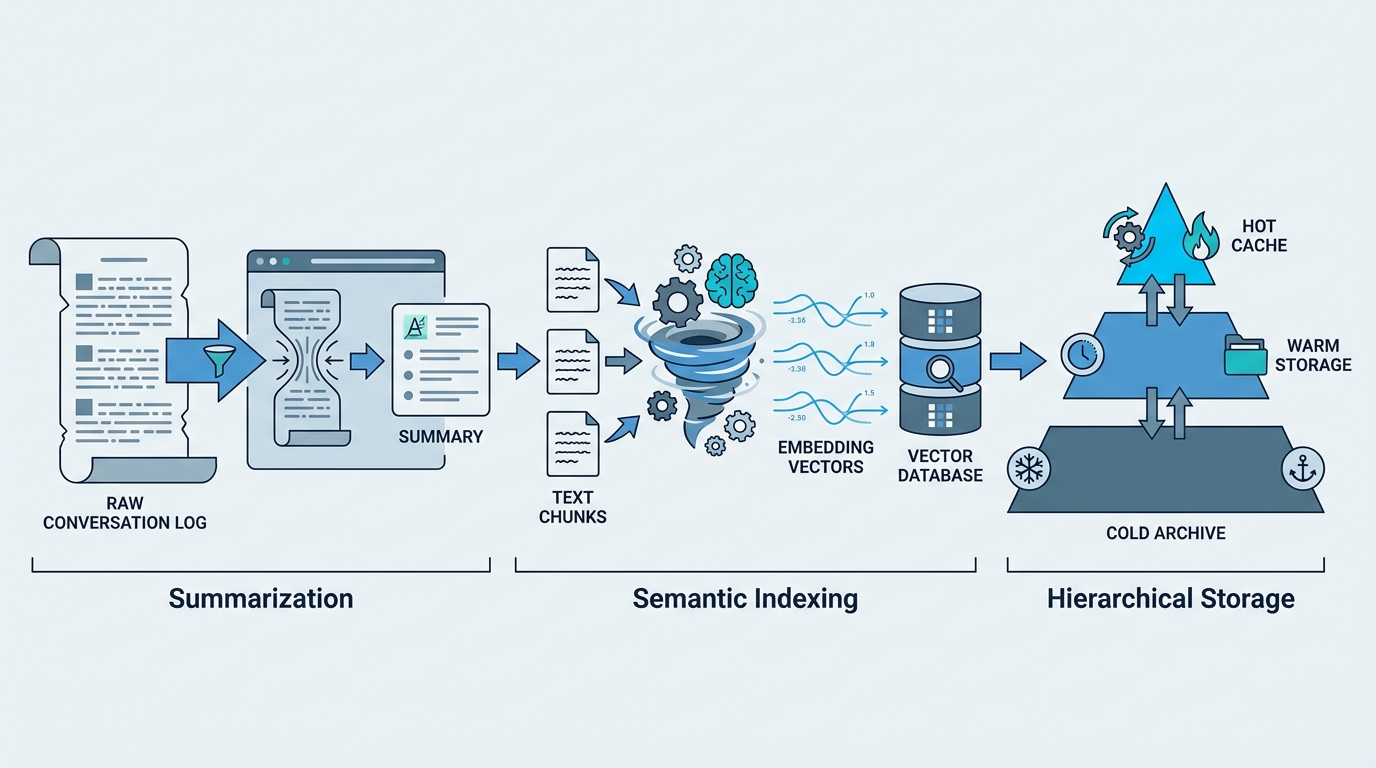
Compression and Summarization
To reduce token overhead, many systems compress conversation history. Techniques include:
- Extractive summarization: Pull out key facts and decisions from the conversation
- Abstractive summarization: Generate concise summaries of conversation segments
- Hierarchical compression: Summarize summaries, creating a multi-level hierarchy
Compression reduces token consumption significantly—some systems report 80-92% reductions—but introduces the risk of losing important details. The challenge is determining what information is essential and what can be safely discarded.
Semantic Indexing and Retrieval
Rather than storing raw text, semantic indexing converts information into embeddings and stores them in vector databases. When the agent needs context, it performs a semantic search: "Find memories related to the current query." This approach is more efficient than replaying full history and better at capturing conceptual relationships.
The trade-off is added complexity: the system must maintain embeddings, manage vector database infrastructure, and handle the latency of semantic search queries.
Hierarchical Memory Organization
Some advanced systems organize memory hierarchically, similar to how human memory works. Recent, frequently-accessed information is kept in fast, small storage (like a cache). Older or less-frequently-accessed information moves to slower, larger storage. The system dynamically promotes or demotes information based on relevance and access patterns.
This approach balances efficiency with retention, but requires sophisticated management logic to determine what information should be at each level.
Implementation Approaches
In-Context Learning
In-context learning stores relevant memories directly in the prompt context. The agent retrieves the most relevant memories for the current task and includes them in the prompt. This is simple and transparent—the model can directly see and reason about the memories—but limited by context window size.
External Memory Systems
External memory systems store information outside the model's context window and retrieve it on-demand. This scales better than in-context learning but adds latency and complexity. The agent must decide what to retrieve, fetch it from external storage, and incorporate it into the prompt.
Hybrid Architectures
Many production systems combine multiple approaches. For example:
- Use short-term memory (sliding window) for immediate context
- Use semantic search on long-term memory for relevant historical information
- Compress older information to reduce storage costs
- Maintain episodic records of important decisions and outcomes
Tool Integration Patterns
Some agents use external tools to manage memory. For example, an agent might use a note-taking tool to explicitly store important information, or a database query tool to retrieve facts. This makes memory management explicit and auditable but requires the agent to actively decide when to store and retrieve information.
Challenges and Trade-offs
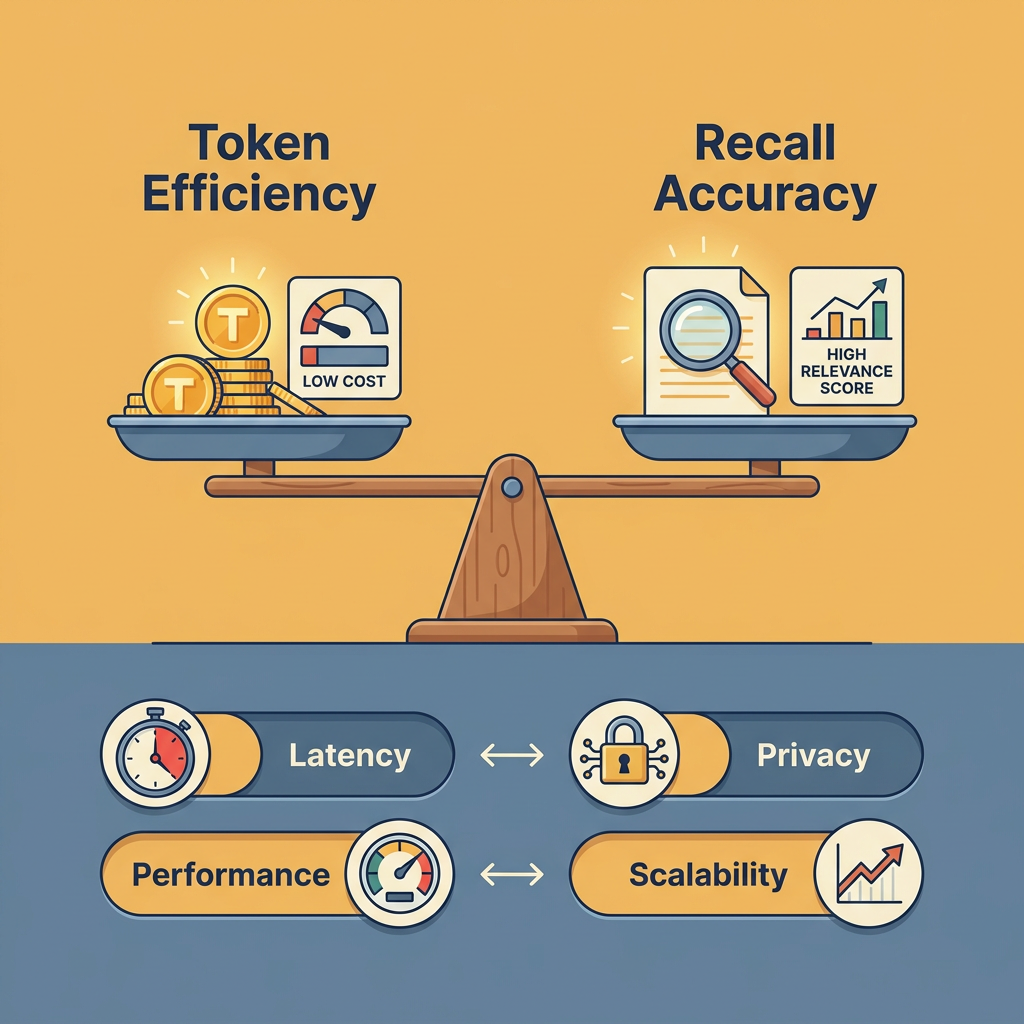
Token Efficiency vs. Recall Accuracy
Including more memory in the context improves recall accuracy—the agent has more information to work with—but increases token consumption and costs. The optimal balance depends on the specific use case and budget constraints.
Latency and Performance
Retrieving memories from external systems adds latency. A semantic search query might take 100-500ms, which is acceptable for some applications but problematic for real-time interactions. Caching and indexing strategies can mitigate this, but add complexity.
Privacy and Security
Agent memory systems must handle sensitive information carefully. If an agent serves multiple users or projects, memory isolation is critical—information from one user or project must never leak into another. This requires careful system design and access controls.
Scalability Concerns
As agents accumulate more memories, retrieval becomes more challenging. Vector databases can scale to millions of embeddings, but performance degrades without proper indexing and optimization. Deciding what information to retain and what to discard becomes increasingly important.
Real-World Applications
Agent memory systems are proving valuable across multiple domains:
Customer Support: Support agents with memory can recall previous tickets, understand customer history, and provide personalized assistance without requiring customers to repeat information.
Coding Assistants: Agents that remember a codebase's architecture, naming conventions, and design decisions can provide more contextually appropriate suggestions and avoid contradicting earlier recommendations.
Research and Analysis: Research agents can accumulate knowledge across multiple sessions, building on previous analyses and maintaining consistency in methodology and findings.
Multi-Turn Task Execution: For complex tasks spanning hours or days, memory enables agents to maintain context, track progress, and make decisions based on accumulated information.
One concrete example is MemClaw, an agent memory platform that implements project-scoped memory isolation. When professionals manage multiple clients or codebases simultaneously, MemClaw ensures that information from one project never contaminates another—a critical requirement for consultants, developers, and researchers working across parallel engagements. By maintaining strict project boundaries in memory, agents can serve multiple concurrent contexts without confusion or information leakage.
Common Questions About Agent Memory
Q: How much memory do agents actually need? A: It depends on the task. Short conversations might need only a few turns of context. Long-running tasks might benefit from weeks or months of accumulated information. The key is matching memory capacity to task requirements.
Q: Can agents learn from memory? A: Yes, but it requires explicit design. Agents can extract patterns from stored memories and adjust their behavior accordingly. However, this is different from true learning—the agent's underlying model weights don't change.
Q: How do you prevent memory from becoming corrupted or outdated? A: Through careful management: regular audits, version control for important memories, and mechanisms to correct or delete outdated information. Some systems use human-in-the-loop review for critical memories.
Conclusion
Agent memory is no longer a nice-to-have feature—it's a fundamental architectural requirement for production AI agents. The landscape of approaches is diverse, from simple conversation history to sophisticated semantic indexing and hierarchical organization. The right approach depends on your specific use case, performance requirements, and constraints.
As the field matures, we're seeing convergence around hybrid architectures that combine multiple memory types and retrieval strategies. The future likely involves more sophisticated memory management, better tools for auditing and controlling agent memory, and standardized approaches to memory isolation and privacy. For teams building agents today, understanding these memory strategies is essential for designing systems that are reliable, efficient, and trustworthy.