
You deploy an AI agent. It works in testing. Then in production it contradicts a decision it made four steps ago, re-fetches data it already retrieved, and produces a wrong answer with complete confidence — no crash, no error, just a quietly broken result.
That gap between "agent works in a demo" and "agent works reliably at scale" is exactly what agent management addresses.
This guide covers what agent management means, why it's harder than it looks, the four pillars every team needs, and how dedicated platforms handle the work.
What Is Agent Management?
Agent management is the practice of controlling, monitoring, and maintaining AI agents across their full operational lifecycle — from initial deployment through versioning, scaling, and eventual retirement.
It's distinct from agent building. Building is about designing what an agent does: its tools, its prompts, its reasoning flow. Management is everything that happens after you ship it: keeping it running correctly, catching failures, controlling costs, and preserving context across sessions.
This applies to single agents and multi-agent systems alike. A single agent that loses its memory between sessions needs management. A system of ten coordinated agents that can route tasks into infinite loops needs management even more.
The term "AI agent management" has emerged alongside the broader shift from one-off LLM calls to persistent, autonomous agents that take real actions in real systems. As those agents multiply, the operational burden grows fast.
Why Agent Management Is Hard
Three problems make agent management genuinely difficult — not just operationally complex, but structurally different from managing traditional software.
1. Context Drift and Memory Loss
LLMs are stateless by default. Every new session starts from scratch. Without persistent memory, an agent working on a multi-week project forgets what it decided last Tuesday. It re-asks questions already answered, contradicts earlier choices, and forces users to re-explain context they've already provided.
In multi-step workflows, this compounds: an agent eight tool calls deep can lose track of constraints set at the start of the session, producing outputs that look correct but violate requirements established earlier.
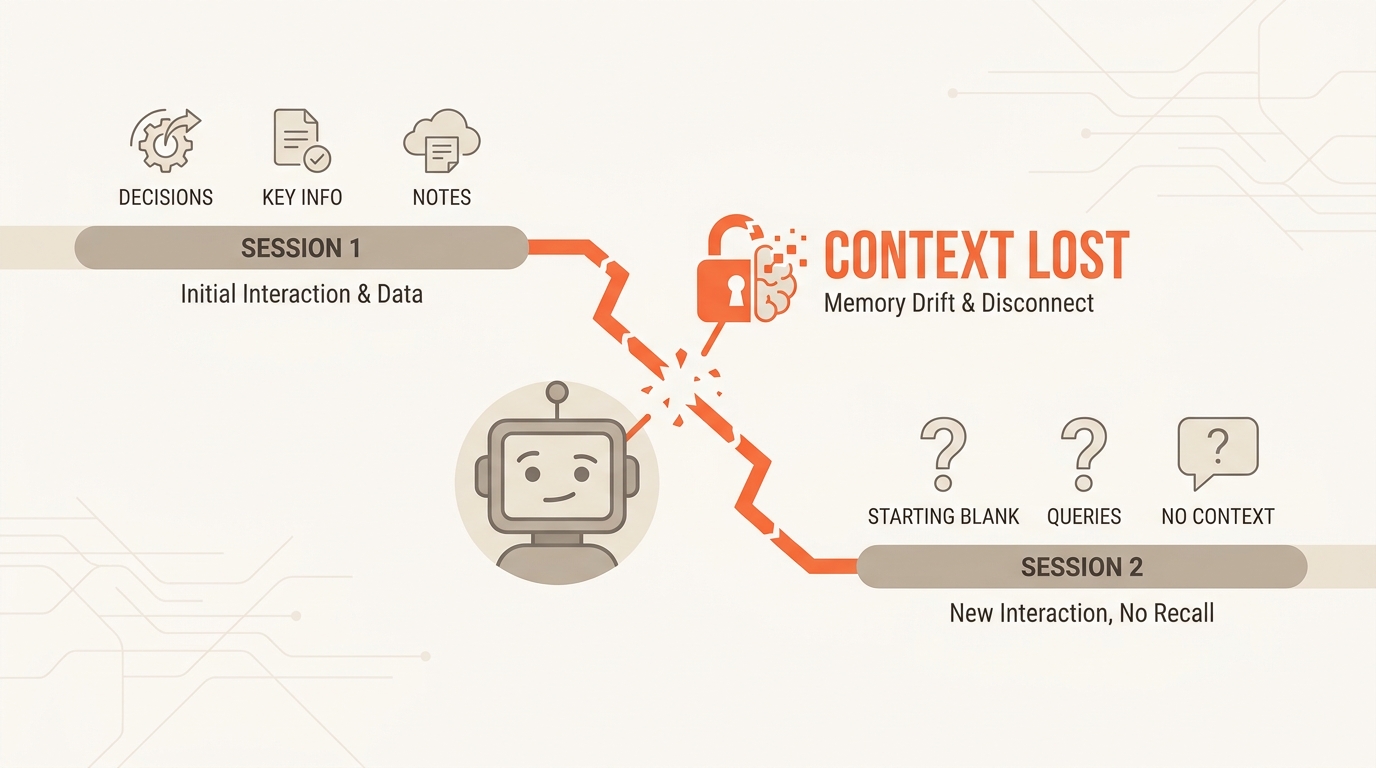
2. Silent Failures
Traditional software fails loudly — exceptions, stack traces, non-zero exit codes. Agents fail quietly. A wrong output doesn't crash anything; it just gets passed downstream as if it were correct. By the time the error surfaces, it may have propagated through several subsequent steps.
Research on multi-agent systems puts production failure rates between 41% and 86% depending on task complexity. Most of those failures aren't crashes — they're wrong answers that looked right.
3. Coordination Chaos
In multi-agent systems, agents with slightly ambiguous instructions can bounce tasks back and forth without resolving them. One agent escalates to another, which escalates back, creating routing loops that consume tokens and produce nothing. Debugging these failures is hard because each individual agent may behave correctly in isolation — the failure lives in the space between them.
The 4 Pillars of Agent Management
Effective agent management covers four areas. Teams that skip any one of them tend to discover why it matters the hard way.
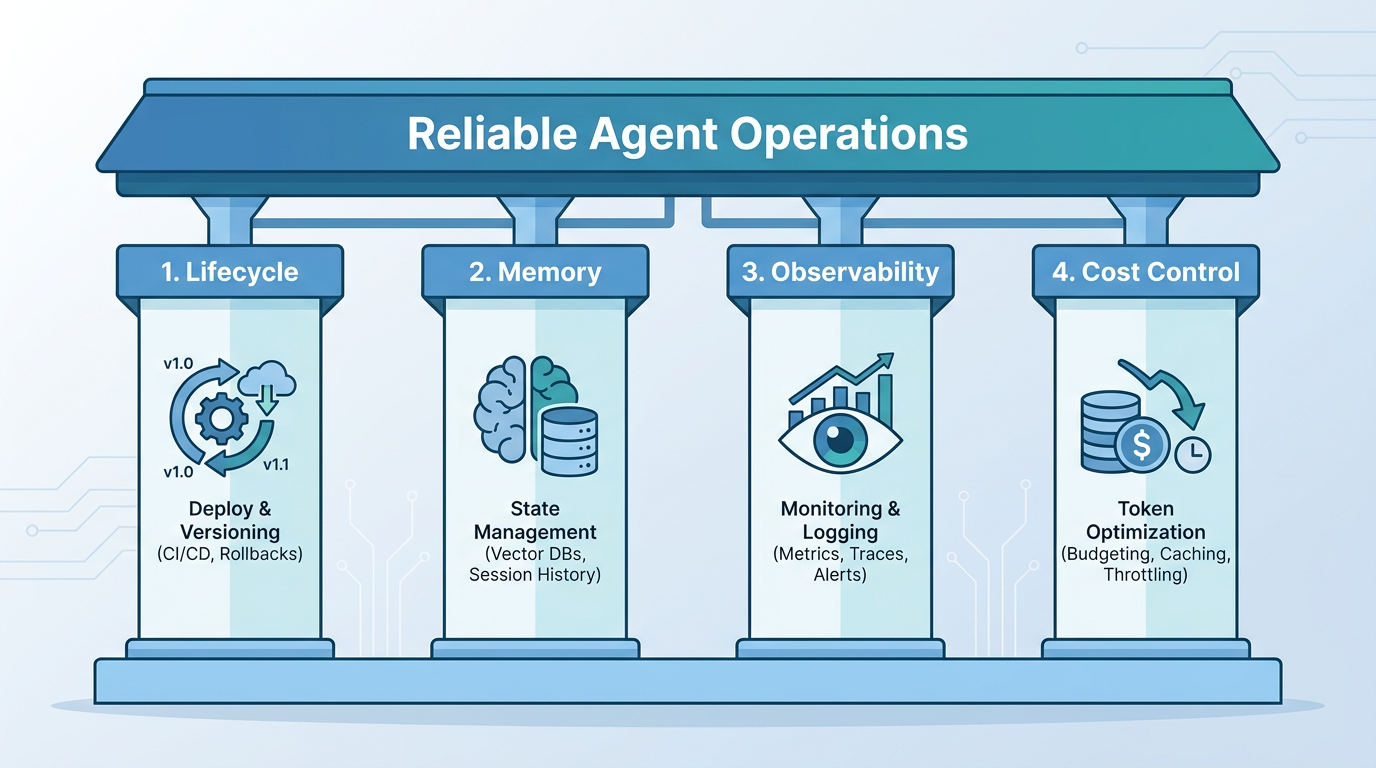
1. Lifecycle Management
Agents need the same lifecycle discipline as any production software: versioned deployments, rollback capability, staged rollouts, and a clear retirement path. Unlike a database rollback, rolling back an agent that has already taken actions in the world is complex — which makes getting the deployment right the first time more important.
2. Memory and State
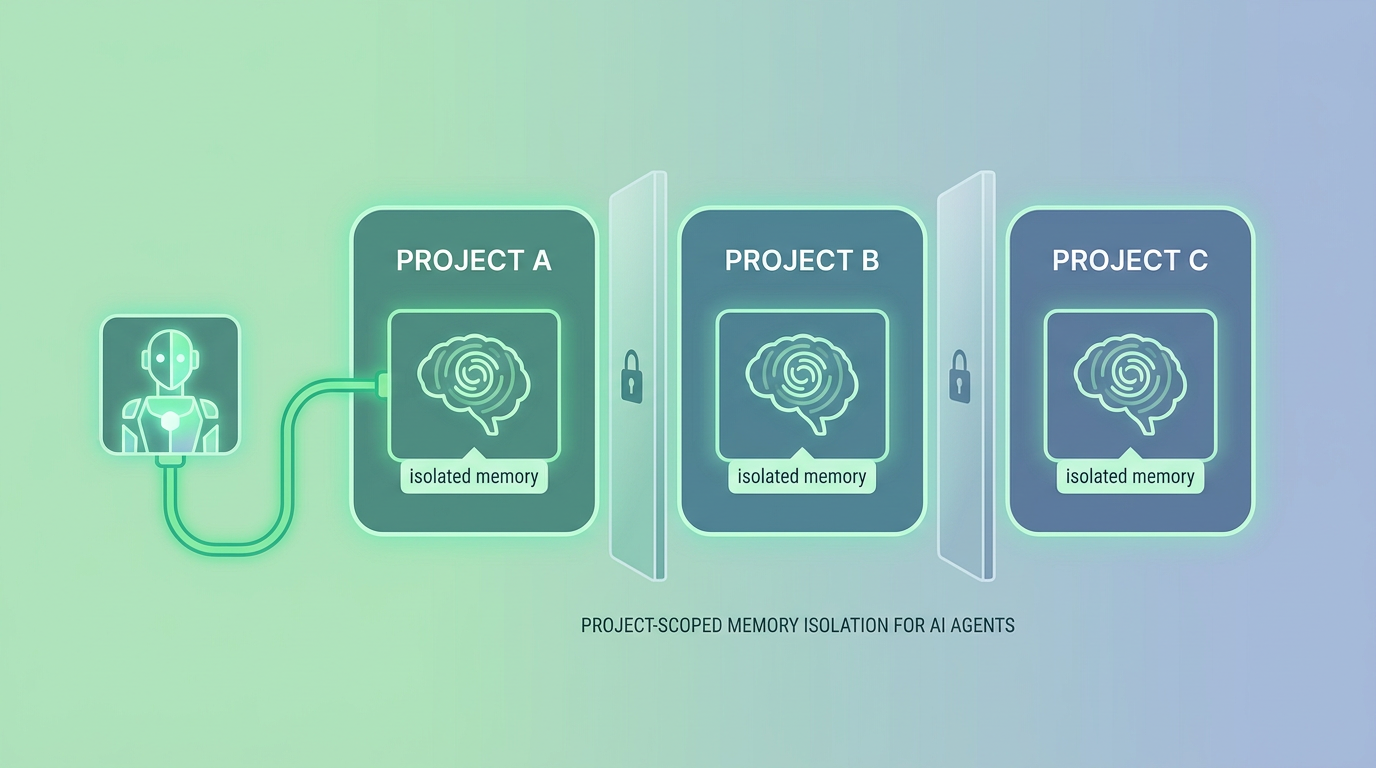
Persistent, project-scoped memory is the foundation of reliable agent behavior. Without it, every session is a cold start. With it, agents can pick up where they left off — preserving key decisions, architecture notes, and task state across sessions and across team members.
MemClaw addresses this directly with project-scoped memory isolation: each project maintains its own memory boundary, so no context bleeds between clients or workstreams. Agents load only the memory relevant to the current task rather than accumulating noise from all past conversations.
3. Observability
You can't debug what you can't see. Agent observability means distributed tracing across tool calls, structured logging of reasoning steps, and alerting on anomalous patterns — not just errors. Because agent failures are non-deterministic, reproducing a bug requires capturing enough execution context to reconstruct what happened.
4. Cost Control
Multi-agent workflows consume tokens at a rate that surprises most teams. A single user request can trigger planning, tool selection, execution, verification, and retry loops — consuming roughly five times more tokens than a direct LLM call. Without token budgets per agent and per workflow, a single runaway job can exhaust a monthly budget.
How AI Agent Management Platforms Work
A dedicated AI agent management platform provides a centralized control plane so you're not building these capabilities from scratch for every project.
Core capabilities typically include:
- Centralized monitoring — a single view across all agents, their status, and their recent activity
- Identity and access control — which agents can call which tools, with audit trails
- Memory management — persistent context storage that survives session boundaries
- Cost attribution — token usage tracked per agent, per project, per user
MemClaw is a concrete example of this approach for OpenClaw users. It adds project-scoped persistent memory to OpenClaw, letting agents restore full context with a single command — "Open the project I worked on most recently" — rather than requiring users to re-explain background at the start of every session.
The install is a single command. Once active, MemClaw isolates memory by project so a developer juggling three client codebases doesn't get context from one bleeding into another. A consultant tracking six clients with separate pricing and requirements gets accurate, account-specific responses every time.
The web interface lets you inspect, search, and manage what your agent remembers across all projects — giving you visibility into stored context before it affects agent behavior.
Try MemClaw — free to install and use
Agent Management Best Practices
A few principles that hold across platforms and frameworks:
Define agent boundaries before you deploy. Ambiguous scope is the root cause of most coordination failures. Each agent should have a clear, narrow responsibility. If two agents could plausibly handle the same task, that's a design problem, not a routing problem.
Build observability before you need it. Instrumenting agents after a production failure is painful. Structured logging and tracing should be part of the initial deployment, not an afterthought.
Set token budgets per agent. Hard limits prevent runaway cost spirals. Treat token budgets the way you treat memory limits in traditional software — a constraint, not an afterthought.
Test failure modes, not just happy paths. Agents fail in ways that unit tests don't catch: context drift, tool misuse, routing loops. Dedicated eval suites that probe these failure modes catch problems before production does.
Use project-scoped memory for multi-project work. If your agents touch more than one project or client, memory isolation isn't optional — it's a correctness requirement. Context bleeding between projects produces wrong answers that are hard to trace back to their source.
Frequently Asked Questions
What's the difference between agent management and agent orchestration?
Orchestration is about coordinating agents to complete a task — routing, sequencing, and combining their outputs. Agent management is the broader operational discipline: lifecycle, memory, observability, and cost control. Orchestration is one component of management, not a synonym for it.
Do I need a dedicated AI agent management platform, or can I build my own?
You can build your own, and many teams start that way. The tradeoff is time: building reliable memory persistence, distributed tracing, and cost attribution from scratch takes significant engineering effort. Dedicated platforms let you skip that work and focus on what your agents actually do.
How do I handle memory across long-running agent sessions?
The most reliable approach is project-scoped persistent storage — memory that lives outside the context window and loads on demand. This means agents can resume work after days or weeks without requiring users to re-explain context. Tools like MemClaw implement this as a skill layer on top of OpenClaw, requiring no changes to your agent's core logic.
What causes agents to fail silently in production?
Silent failures usually come from one of three sources: context drift (the agent loses track of earlier constraints), tool misuse (a tool returns unexpected output that the agent treats as valid), or coordination failure in multi-agent systems (an agent passes a wrong intermediate result downstream). Structured logging that captures tool inputs and outputs — not just final answers — is the most effective way to catch these.
What is agent lifecycle management?
Agent lifecycle management covers the full arc of an agent's operational existence: initial deployment, versioning as prompts or tools change, staged rollouts to catch regressions, and eventual retirement when the agent is replaced or decommissioned. It mirrors software release management but adds the complexity that agents take real-world actions that can't always be rolled back.
Wrapping Up
Agent management covers four things: lifecycle discipline, persistent memory, observability, and cost control. Teams that treat these as afterthoughts tend to discover why they matter through production failures.
If you're working with OpenClaw and want a starting point for centralized memory management, MemClaw handles project-scoped memory isolation and context restoration out of the box — free to install, active in under five minutes.